2019. 3. 28. 16:57ㆍ알고리즘/정렬
합병 정렬(merge sort) 알고리즘의 개념 요약
‘존 폰 노이만(John von Neumann)’이라는 사람이 제안한 방법
일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬 에 속하며, 분할 정복 알고리즘의 하나 이다.
분할 정복(divide and conquer) 방법
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
과정 설명
리스트의 길이가 0 또는 1이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는
정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
합병 정렬(merge sort) 알고리즘의 구체적인 개념
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
합병 정렬은 다음의 단계들로 이루어진다.
분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
합병 정렬의 과정
추가적인 리스트가 필요하다.
각 부분 배열을 정렬할 때도 합병 정렬을 순환적으로 호출하여 적용한다.
합병 정렬에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병(merge)하는 단계 이다.

합병 정렬(merge sort) 알고리즘의 예제
배열에 27, 10, 12, 20, 25, 13, 15, 22이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
2개의 정렬된 리스트를 합병(merge)하는 과정
2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트(sorted)로 옮긴다.
둘 중에서 하나가 끝날 때까지 이 과정을 되풀이한다.
만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트(sorted)로 복사한다.
새로운 리스트(sorted)를 원래의 리스트(list)로 옮긴다.

합병 정렬(merge sort)의 시간복잡도
시간복잡도를 계산한다면
분할 단계
비교 연산과 이동 연산이 수행되지 않는다.
합병 단계
비교 횟수
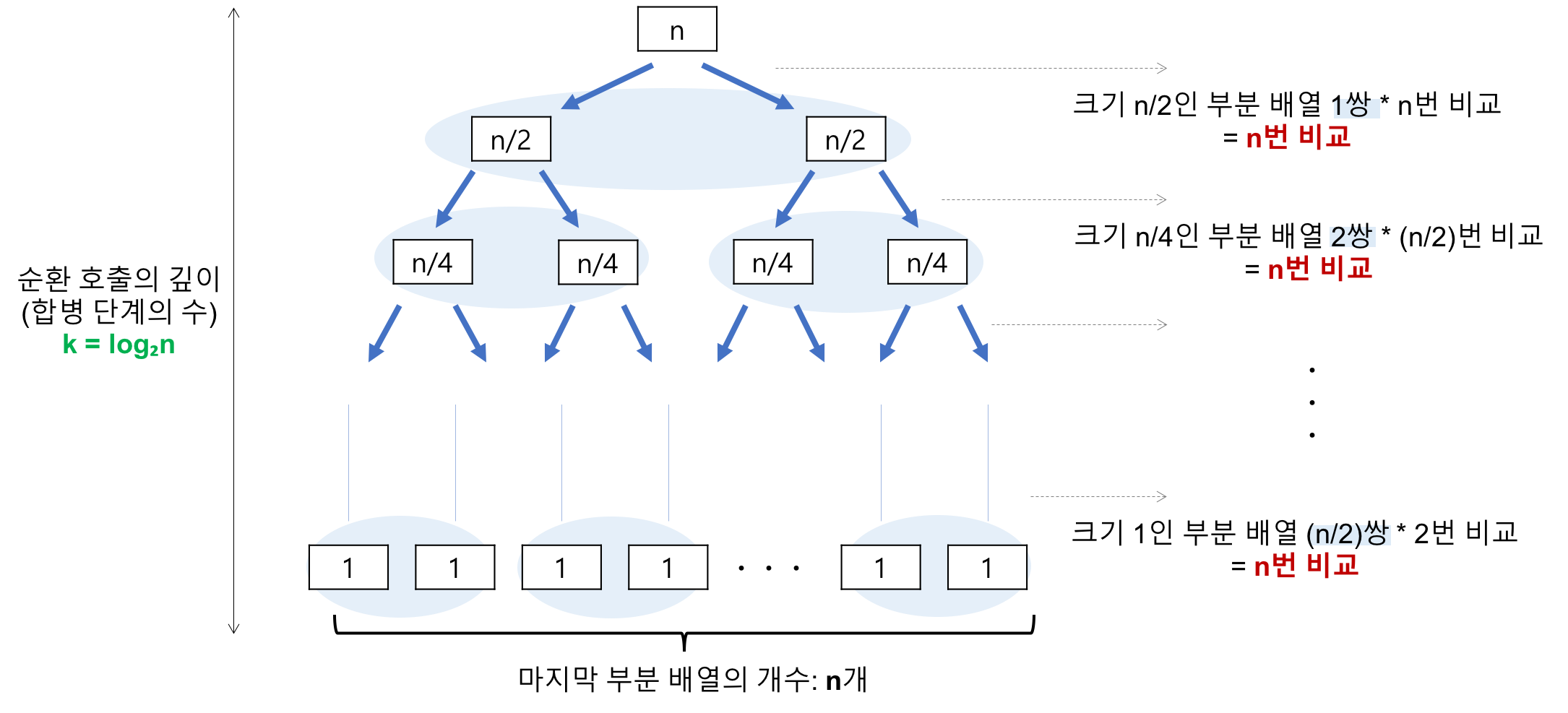
순환 호출의 깊이 (합병 단계의 수)
레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k)했을 때, n=2^3의 경우, 2^3 -> 2^2 -> 2^1 -> 2^0 순으로 줄어들어 순환 호출의 깊이가 3임을 알 수 있다. 이것을 일반화하면 n=2^k의 경우, k(k=log₂n)임을 알 수 있다.
k=log₂n
각 합병 단계의 비교 연산
크기 1인 부분 배열 2개를 합병하는 데는 최대 2번의 비교 연산이 필요하고, 부분 배열의 쌍이 4개이므로 24=8번의 비교 연산이 필요하다. 다음 단계에서는 크기 2인 부분 배열 2개를 합병하는 데 최대 4번의 비교 연산이 필요하고, 부분 배열의 쌍이 2개이므로 42=8번의 비교 연산이 필요하다. 마지막 단계에서는 크기 4인 부분 배열 2개를 합병하는 데는 최대 8번의 비교 연산이 필요하고, 부분 배열의 쌍이 1개이므로 8*1=8번의 비교 연산이 필요하다. 이것을 일반화하면 하나의 합병 단계에서는 최대 n번의 비교 연산을 수행함을 알 수 있다.
최대 n번
순환 호출의 깊이 만큼의 합병 단계 * 각 합병 단계의 비교 연산 = nlog₂n
이동 횟수
순환 호출의 깊이 (합병 단계의 수)
k=log₂n
각 합병 단계의 이동 연산
임시 배열에 복사했다가 다시 가져와야 되므로 이동 연산은 총 부분 배열에 들어 있는 요소의 개수가 n인 경우, 레코드의 이동이 2n번 발생한다.
순환 호출의 깊이 만큼의 합병 단계 * 각 합병 단계의 이동 연산 = 2nlog₂n
T(n) = nlog₂n(비교) + 2nlog₂n(이동) = 3nlog₂n = O(nlog₂n)
소스코드
#include <iostream>
using namespace std;
#define MAX_SIZE 10
void merge(int arr[], int left, int mid, int right) {
int i, j, k;
i = left;
j = mid + 1;
k = left; // 결과 배열의 인덱스
int temp_arr[MAX_SIZE]; // 임시저장 배열 생성
//left부터 mid까지의 블록과 mid+1부터 right 까지의 블록을 서로 비교하는 부분 i = left, j = right
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) { // left 인덱스 값이 right 인덱스 값보다 작으면 left 인덱스값 임시 배열에 저장
temp_arr[k] = arr[i];
i++; // 왼쪽 인덱스값이 저장되었으므로 다음으로 넘어가기위해 증가
}
else { // 아니라면 right 인덱스값 임시 배열에 저장
temp_arr[k] = arr[j];
j++; //오른쪽 인덱스 저장값 위와 마찬가지로 증가
}
k++; //if문을 벗어나서 숫자가 저장되었으면 다음 인덱스에 저장되기위해 k 값도 증가
}
// left 블록의 값은 다 처리되었는데 right 블록의 index가 아직 남아있을 경우
// right index를 순차적으로 결과 result에 복사
if (i > mid) { // i>mid = left>mid ==> left에 블록의 값이 다 처리됬다.
for (int m = j; m <= right; m++) {
temp_arr[k] = arr[m];
k++;
}
}
else { // left 블록의 index가 아직 남아있을 경우 left index를 순차적으로 결과 result에 복사
for (int m = i; m <= mid; m++) {
temp_arr[k] = arr[m];
k++;
}
}
// 임시배열에 저장했던 정렬된 배열값 복사
for (int m = left; m <= right; m++) {
arr[m] = temp_arr[m];
}
}
void mergesort(int arr[], int left, int right) {
int mid; //중앙값 선언
// 분할이 다 되지 않았을 경우 if문 실행
if (left < right) {
mid = (left + right) / 2;
mergesort(arr, left, mid); // 왼쪽 블록 분할
mergesort(arr, mid + 1, right); // 오른쪽 블록 분할
merge(arr, left, mid, right); // 분할된 블록 병합
}
}
int main() {
int merge[] = { 15, 2, 24, 18, 7, 13, 12, 4, 21, 9 };
int size = sizeof(merge) / sizeof(merge[0]);
mergesort(merge, 0, size - 1);
for (int i = 0; i < size; i++) {
cout << merge[i] << " ";
}
cout << endl;
system("pause");
return 0;
}
결과 값

'알고리즘 > 정렬' 카테고리의 다른 글
| 힙 정렬(Heap Sort) (0) | 2019.03.28 |
|---|---|
| 퀵 정렬(Quick Sort) (0) | 2019.03.28 |
| 삽입 정렬(insertion sort) (0) | 2019.03.28 |
| 버블 정렬(Bubble Sort) (0) | 2019.03.28 |
| 선택 정렬(Selection Sort) (0) | 2019.03.28 |