2019. 3. 28. 20:20ㆍ알고리즘/정렬
- 선형시간 정렬 알고리즘 : 계수 정렬 -
앞 장에서 설명한 정렬 알고리즘은 비교 연산을 통해서 정렬을 하는 방식을 취했다. 비교 연산은 두 개의 원소의 관계를 크고 작음에 따라 비교하여 판단하는 연산이다. 비교연산으로 정렬하는 방법은 아무리 빨라도 nlgn보다는 빠를 수가 없다. 하지만 비교를 하지 않는 방법으로 하면 이 보다 따른 시간으로 수행이 가능하다. 이런 방법으로 계수 정렬이 있다. 계수 정렬은 실제 숫자를 세는 방법으로 숫자가 몇 개인지를 기록한다. x라는 입력은 x보다 작은 원소의 개수가 I-1개라면 정렬 후에 I번째에 위치해야 한다. x보다 작은 원소의 개수는 원소를 개수를 세어서 확인할 수 있다.
계수 정렬에 대한 예를 한 번 들어보자. A라는 배열이 입력으로 들어왔다고 가정한다. A라는 배열은 <2, 5, 3, 0, 2, 3, 0, 3> 이라는 배열이다. 이 배열을 정렬하기 위해 개수를 세는 또 다른 배열인 count라는 배열이 필요하다. 우선 A 배열에서 가장 큰 숫자와 가장 작은 숫자를 찾을 필요가 있다. 그래야 이 배열 안에 특정 숫자들이 몇 개인지를 표현할 수 있게 된다. 배열 A에서 가장 작은 숫자는 0이다. 가장 큰 숫자는 5이다. 이 두 숫자를 고려해서 count 배열은 6의 크기를 가지는 배열이 된다. count라는 배열의 0 index 에는 A라는 배열에서 0이라는 숫자의 개수를 의미하고 1 index는 A 배열에 1이라는 숫자가 몇 개 있는지를 의미하게 된다. 가장 큰 숫자가 5이므로 5 index는 A 배열의 5의 개수를 의미하는 것이다. 이제 정렬을 위해 count 배열을 작성해보자. A 배열에서 순서대로 관찰하여 count 배열을 업데이트 해 나갈 것이다. A 배열의 첫 번째 자리가 2라는 값을 가지므로 count 배열의 2 index에 1을 더해준다. A 배열의 두 번째 자리는 5의 값을 가지므로 count 배열의 5 index에 1을 더해준다. 이렇게 계속 진행해 가면서 A의 마지막 index의 값까지 진행하여 count를 업데이트 시킨다.

그러면 어떻게 이 count 배열을 가지고 A를 정렬할까? count 배열은 각 숫자에 대한 개수가 들어가 있다. 따라서 쉽게 생각해서 각 index 순서대로 개수만큼 배열에 넣어주면 정렬이 되게 되는 것이다.
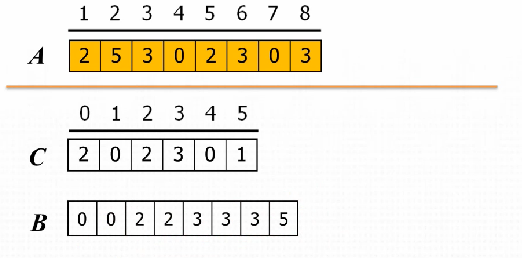
그런데 새로 정렬된 배열을 만들기 위해서 count 배열을 조금 변형하면 편하게 진행할 수 있다. 그것은 바로 count 배열에 해당하는 각각의 값을 처음 index에서 시작하여 값을 쌓아서 다음 index에 적용시키는 것이다. 이렇게 하게 되면 count 배열에 해당하는 값들이 새로 만들어질 배열에서 index 값을 의미하게 된다. 앞의 예시에서 변형시키게 되면 count 배열은 다음과 같이 변형이 가능하다.

이를 이용하게 되면 마지막 index의 값은 새로 정렬된 배열의 크기가 되게 된다. 이제 처음의 A 배열을 정렬하기 위해서 A 배열의 마지막 값부터 count 배열에 값을 따라 index를 지정받아 그 자리에 값을 넣게 된다.
위의 과정에 대한 Pseudo code를 살펴보면 다음과 같다. 이와 같은 방식을 사용하면 수행 시간이 O(n) 이상으로 올라가지 않게 된다.

소스코드
#include <iostream>
using namespace std;
void see(int *A, int p, int r)
{
int i;
for (i = p; i <= r; i++)
cout << A[i] << endl;
}
//1구역 pivot 보다 작거나 같은 원소들
//2구역 pivot 보다 큰 원소들
//3구역 아직 정해지지 않은 원소들
int partition(int arr[], int left, int right) {
int pivot = arr[right]; // 기준원소 설정
int i = left - 1; // i 는 1구역의 끝지점
for (int j = left; j < right; j++) { //j는 3구역의 시작지점
if (arr[j] <= pivot) {
swap(arr[++i], arr[j]); //i값 증가 후 arr[i] arr[j] 교환
}
}
swap(arr[i + 1], arr[right]); //기준원소와 2구역 첫 원소 교환
return i + 1;
}
int selection(int *A, int p, int r, int i, int size) //배열 A에서 i번째 작은 원소를 찾는다
{
if (p == r) //원소가 하나뿐인 경우 i는 반드시 1
return A[p];
int q = partition(A, p, r); // q : 기준원소의 위치(인덱스)
// k : 기준원소보다 +1 하는데, 이것은 후반부 처음 시작위치이며, 후반부로 호출됬을경우, 찾을 원소 i에 -k를 한다.(전반부를 원소들을 제외)
int k = q - p + 1; //k= 기준원소가 전체에서 k번째 작은 원소임을 의미
// 찾을 i번째로 작은원소가 기준원소(k)보다 큰 경우(찾을 원소는 후반부에 있음)
if (i > k) // 왼쪽 그룹으로 범위를 좁힘
{
return selection(A, q + 1, r, i - k, size);
}
// 찾을 i번째로 작은원소는 기준원소와 같을 경우
else if (i == k)
return A[q];
// 찾을 i번째로 작은원소가 기준원소보다 작은 경우
else
{
return selection(A, p, q - 1, i, size);
}
}
int main()
{
int i, result;
int array[10] = { 31, 8, 48, 73, 11,3,20,29,65,15 };
int k = sizeof(array) / sizeof(array[0]);
cout << endl;
cout << "몇 번째로 작은 원소를 찾을 것인지 입력 : " << endl;
cin >> i;
cout << "전체 데이터 : " << endl;
see(array, 0, k-1);
result = selection(array, 0, k-1, i, k-1);
cout << endl << i << " 번째로 작은 원소 : " << result << endl << endl;
system("pause");
return 0;
}
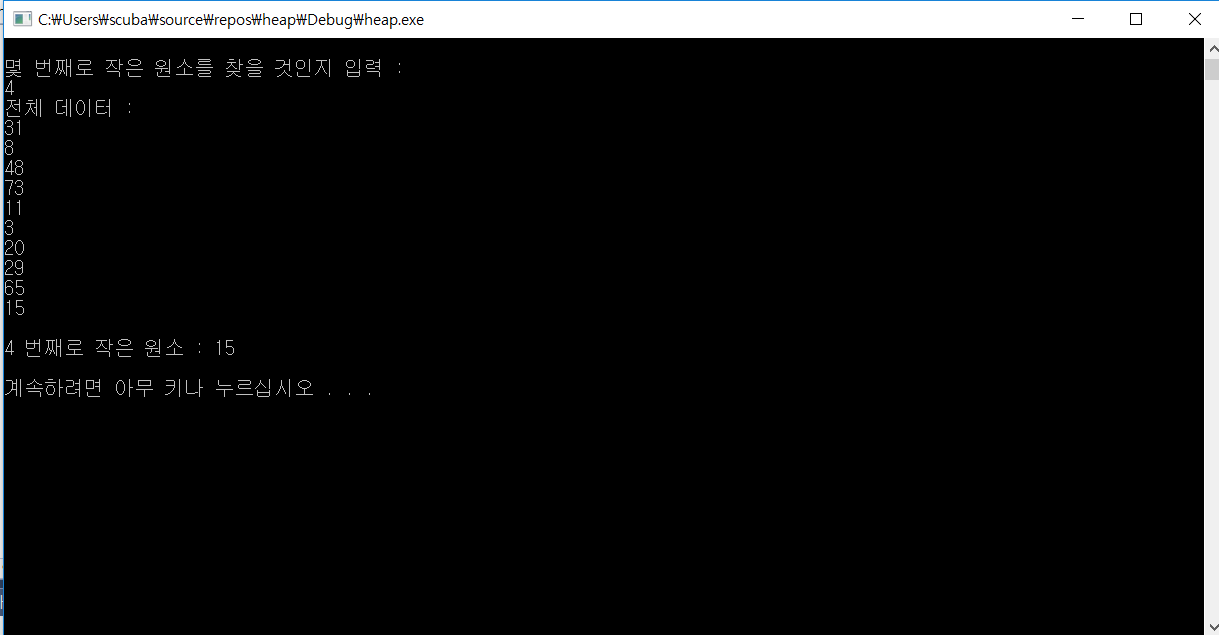
결과 값
'알고리즘 > 정렬' 카테고리의 다른 글
| 정렬 알고리즘 시간복잡도 (0) | 2019.03.28 |
|---|---|
| 힙 정렬(Heap Sort) (0) | 2019.03.28 |
| 퀵 정렬(Quick Sort) (0) | 2019.03.28 |
| 병합정렬(merge sort) (0) | 2019.03.28 |
| 삽입 정렬(insertion sort) (0) | 2019.03.28 |